В.Г. Олифер Базовые технологии компьютерных сетей (ознакомительное качество) Высокое качество PDF, для печати :-)
Михаил Гук. Интерфейсы ПК. Справочник (ознакомительное качество) Высокое качество PDF, для печати :-)
| Главная | Главная по Компьютерным сетям |
Предыдущая | Оглавление | Следующая
Глава 9. Маршрутизаторы (часть2)
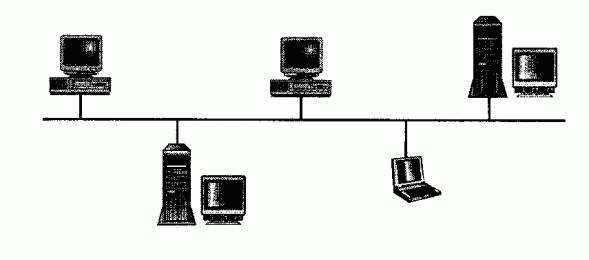
В простейшей одноранговой сети, которую можно себе представить (см. рис. 9.1), любой компьютер имеет право инициировать процедуру обмена данными с другими компьютерами.
Однако с увеличением количества компьютеров такая архитектура уже не удовлетворяет требованиям пользователей. Вот далеко не полный список основных проблем:
Решить эти проблемы в состоянии сегментация. Однако одновременно с разбиением сети на отдельные сегменты необходимо обеспечить механизм взаимодействия хостов сегментов. Этот механизм предполагает селективную передачу данных между сегментами на определенном уровне сетевого стека ISO. На рисунке 9.2 показано соответствие физических устройств уровням модели OSI.
Маршрутизаторы функционируют на сетевом уровне. В этой главе предполагается, что сетевой уровень представлен протоколом IP (версия 4), который на настоящий момент чрезвычайно распространен. Однако все изложение в полной мере относится к остальным протоколам сетевого уровня.
Принципы маршрутизации и ретрансляции
Маршрутизация считается процедурой, которая на порядок сложнее коммутирования/ретрансляции второго уровня, поскольку позволяет не учитывать физические аспекты сети. Всем машинам в маршрутизируемой сети присваивается адрес сетевого уровня стандартного формата (например, IP-адрес). При этом не имеет значения, объединены машины в архитектуру Ethernet, Token Ring, FDDI или просто в глобальную сеть.
Адреса канального уровня (например, МАС-адреса) в масштабах определенной сети являются уникальными идентификаторами. Кроме того, они могут быть уникальными и в более глобальных масштабах - в качестве примера можно привести адреса Ethernet. Адреса сетевого уровня обычно несут больше информации, поскольку состоят из двух частей: адреса сети и адреса хоста. (Например, IP-адрес моего сетевого адаптера 158.84.81.39, где 158.84.81 - адрес сети, а 39. - адрес хоста.)
РИСУНОК 9.1. Простейшая сеть.
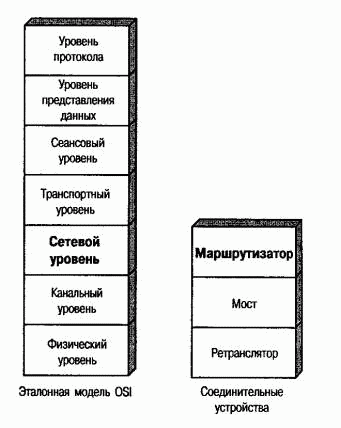
РИСУНОК 9.2. Соответствие устройств уровням модели OSI.
ПРИМЕЧАНИЕ
В данном случае адрес сети включает также адрес подсети.
Мосты в состоянии устанавливать соединение только между сетями с одинаковыми (или очень близкими) протоколами канального уровня. Для маршрутизатора этой проблемы не существует. Допускается устанавливать соединение между любыми двумя сетями (при условии, что их хосты используют один и тот же протокол сетевого уровня).
Взаимодействие сетевого и канального уровней
Канальный уровень расположен под сетевым. Для обеспечения их взаимодействия необходимы какие-то «склеивающие» протоколы. Для преобразования адресов сетевого уровня (третий уровень) в адреса канального уровня (второй уровень) используется Протокол разрешения адресов (ARP - Address Resolution Protocol), a для преобразования адресов второго уровня в адреса третьего уровня - Протокол обратного разрешения адресов (RARP- Reverse Address Resolution Protocol).
ARP обычно используется для разрешения IP-адресов, тем не менее он определен как независимый протокол сетевого уровня. Чаще всего в роли канального уровня выступает Ethernet. Соответственно в примерах разделов этой главы, посвященных протоколам ARP и RARP, упоминаются IP и Ethernet, однако сформулированные концепции будут справедливы для других протоколов.
Протокол разрешения адресов
Адреса сетевого уровня являются некими абстрактными понятиями, которые присваиваются системным администратором - сетевому уровню нет необходимости заботиться о свойствах нижележащего канального уровня. Однако сетевые адаптеры в состоянии взаимодействовать друг с другом лишь с помощью адресов второго уровня, который зависит от типа сети. Адреса третьего уровня преобразуются протоколом ARP в упомянутые адреса второго уровня (аппаратные).
Вовсе необязательно включать запрос ARP в каждую отсылаемую дейтаграмму - в локальной таблице ARP кэшируются известные пары <IР-адрес, аппаратный адрес>. В результате в сети вращается минимальное количество пакетов ARP. Использование протокола разрешения адресов не связано с какими-то дополнительными проблемами. Единственной исключительной ситуацией считается обнаружение конфликтных адресов третьего уровня. ARP является достаточно простым протоколом, но некоторые нюансы требуют дополнительных объяснений.
Общий обзор
Если устройству А необходимо переслать дейтаграмму устройству В, располагая при этом только его IP-адресом (b-ip), предварительно следует узнать аппаратный адрес устройства В (в-hard). Устройство А отсылает всем устройствам пакет ARP с указанием IP-адреса, для которого необходимо определить соответствующий аппаратный адрес. Устройство В получает пакет и отвечает на него конкретно устройству А. Последнее в результате получает искомый аппаратный адрес устройства В (см. рис. 9.3).
Обратите внимание, на запрос откликается только устройство В, несмотря на то, что другие сетевые устройства также могут располагать соответствующей информацией. Эта еще одна гарантия получения корректной и не устаревшей информации.
Следует заметить, что запрос ARP будет транслироваться лишь до следующего шлюза, а это не всегда позволяет пакету достигнуть необходимого IP-адреса. Предположим, устройство А должно переслать дейтаграмму устройству В, но после анализа таблицы маршрутизации возникает необходимость передать пакет через маршрутизатор С. Тогда в запросе ARP будет фигурировать адрес маршрутизатора С, а не сетевого устройства В (см. рис. 9.4).
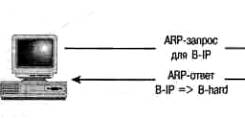
РИСУНОК 9.3. Обмен пакетами ARP.
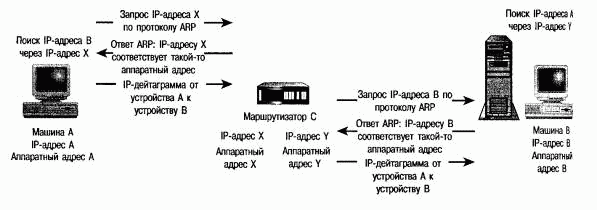
РИСУНОК 9.4. Обмен пакетами ARP через маршрутизатор.
Что происходит после получения пакета ARP
Показанная на рисунке 9.5 блок-схема достаточно подробно иллюстрирует реакцию маршрутизатора на получение пакета ARP. Обратите внимание, дополнительно к отосланному пакету в локальную таблицу ARP вставляется пара <IР-адрес, аппаратный адрес> отправителя. Это вполне логично, поскольку если устройство А хочет поделиться информацией с устройством В, то, скорее всего, устройство В захочет ответить устройству А.
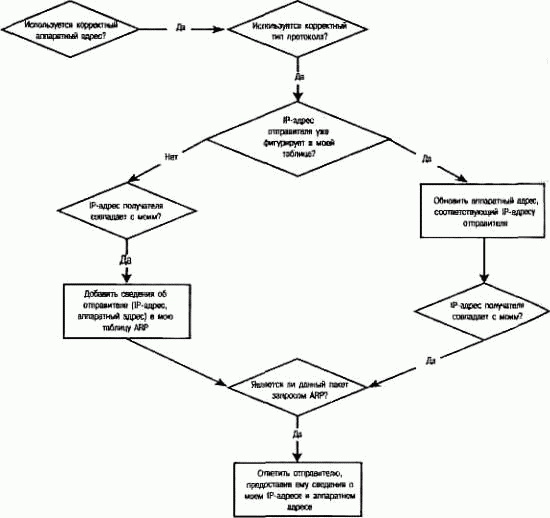
РИСУНОК 9.5. Обработка пакета ARP (в соответствии с данными RFC826).
Конфликты адресов IP
Причиной наиболее распространенного типа ошибок, свойственных протоколу ARP, является конфликт IP-адресов, который возникает в том случае, если двум различным станциям присвоить одинаковые IP-адреса. Все IP-адреса в сети должны быть уникальными.
Конфликтом адресов считается ситуация, когда на один запрос ARP приходит два ответа, в которых фигурируют два различных аппаратных адреса. Это серьезная ошибка, устранить которую достаточно сложно - каким образом выбрать аппаратный адрес, на который следует отправить дейтаграмму?
Чтобы избежать конфликтов IP-адресов, при инициализации сетевое устройство А посылает запрос ARP га свой собственный адрес. Если на запрос никто не отозвался, устройство А обладает уникальным IP-адресом. Но давайте предположим, что устройство В уже использует рассматриваемый IP-адрес. В ответ на запрос ARP оно предоставит сведения о своем аппаратном адресе. Теперь устройство А знает о том, что данный IP-адрес уже используется - устройство не имеет права использовать этот адрес и должно сигнализировать об ошибке.
Однако проблема до сих пор не решена. Предположим, хост С располагает сведениями о том, что конфликтный IP-адрес соответствует аппаратному адресу устройства В. На рисунке 9.3 отчетливо показано, что после получения запроса ARP от сетевого устройства А хост С обновит свою таблицу ARP, поместив в нее аппаратный адрес устройства А. Для исправления подобных ошибок сетевое устройство В («система защиты») обязано вновь разослать запрос ARP для конфликтного адреса IP. Хост С обновит содержимое таблицы ARP таким образом, чтобы конфликтному IP-адресу соответствовал аппаратный адрес устройства В. Статус-кво сети восстановлен, но не следует сбрасывать со счетов вероятность ошибочной пересылки хостом С дейтаграмм IP (предназначенных для устройства В) устройству А, Конечно, такое возможно лишь в определенный момент времени, когда таблица ARP содержит некорректные сведения. К сожалению (или к счастью), поскольку протокол IP не гарантирует доставку данных, подобная ситуация не является серьезной проблемой.
Управление кэш-таблицей ARP
Кэш-таблица ARP представляет собой список пар <IР-адрес, аппаратный адрес>, индексированный по адресам IP. В случае необходимости содержимое таблицы можно отредактировать с помощью специальной команды arp. Некоторые примеры синтаксиса этой команды:
n Добавить в кэш-таблицу статическую запись - arp -s <IР-адрес>, <аппаратный адрес>
n Удалить запись из кэш-таблицы - arp -d <IР-адрес>
n Вывести все записи кэш-таблицы - arp -a
Динамические записи таблицы ARP (такие, которые не были добавлены с помощью команды arp -s), как правило, удаляются с определенной периодичностью. Этот интервал определен в спецификациях протокола TCP/IP, но процедура удаления невостребованных записей может запускаться через заданный администратором промежуток времени. Использование статических адресов ARP Довольно часто статические записи ARP используются для настройки стандартного сервера печати. Эти небольшие устройства могут быть сконфигурированы с помощью протокола Telnet (при условии, что известен их IP-адрес). Единственная проблема заключается в передаче этим устройствам первоначальной информации. Конечно, можно воспользоваться встроенным последовательным портом, однако не все удается быстро найти соответствующий кабель и задать корректные настройки соединения. Предположим, возникла необходимость настроить сервер печати Р, IP-адрес (

РИСУНОК 9.6. Использование статического адреса ARP для настройки сервера печати.
Довольно часто оказывается полезным сконфигурировать сервер печати в одной сети, а использовать его в другой. Для этого можно использовать процедуру, очень похожую на проиллюстрированную на предыдущем рисунке. Пусть известен IP-адрес сервера печати в родной подсети (P-IP). Создайте временный IP-адрес (T-IP) в той подсети, к которой следует подключить сконфигурированный сервер. В таблице рабочей станции (А), подключенной к конфигурируемому серверу, создайте статическую запись ARP, объединяющую адреса P-IP и P-hard, после чего с помощью протокола Telnet задайте соответствие адресу T-IP. Сконфигурируйте сервер печати для использования IP-адреса P-IP. Подключите сервер печати к необходимой подсети, после чего удалите статическую запись в таблице ARP, необходимость в которой отпала (см. рис. 9.7.).
Использование прокси-сервера ARP
Создание прокси-сервера ARP позволяет избежать необходимости конфигурации таблиц маршрутизации на всех хостах. Это оказывается особенно полезным в том случае, если сеть разбита на отдельные подсети, но не все хосты в состоянии различать фрагменты сети (более подробно эта проблема описана в разделе, специально посвященном выделению подсетей).
Основная идея заключается в том, рабочая станция получает право рассылать запросы ARP даже для тех машин, которые не принадлежат ее подсети. В ответ прокси-сервер ARP (часто в этой роли выступает шлюз) предоставляет аппаратный адрес шлюза. Сравните рисунок 9.8, на котором используется кэширование данных ARP, и рисунок 9.4, на котором используются таблицы маршрутизации.
Использование прокси-сервера упрощает задачу конфигурирования хостов. Но одновременно с этим возрастает сетевой трафик (хоть и незначительно). Поскольку необходимо создавать записи для всех IP-адресов, которые не принадлежат локальной подсети, приходится увеличивать объем кэша ARP.
С точки зрения рабочей станции, подключенной через прокси-сервер, весь мир представляет собой огромную физическую сеть без маршрутизаторов!
Адресация IP
В маршрутизируемом протоколе сетевого уровня адрес состоит из двух частей: сетевого адреса и адреса хоста. Вполне логично было бы хранить эту информацию в двух отдельных полях. Под каждое поле будет достаточно зарезервировать 16 бит для обработки максимальных возможных значений адресов. Некоторые протоколы (как-то IPX) именно так и поступают, что позволяет эффективно работать в сетях небольшого и среднего размера.
Можно поступить иначе, сохранив поле адреса хоста небольшим (например, зарезервировав 24 бита для адреса сети и только 8 для адреса хоста). В этом случае можно адресовать множество сетей с небольшим количеством хостов в каждой. Для сетей, количество хостов в которых превышает 256 (28), можно выделить несколько адресов. Недостатком этой схемы адресации считается то обстоятельство, что с увеличением количества сетей в значительной степени возрастает нагрузка на маршрутизаторы.

РИСУНОК 9.7. Использование временного IP-адреса для настройки сервера печати.
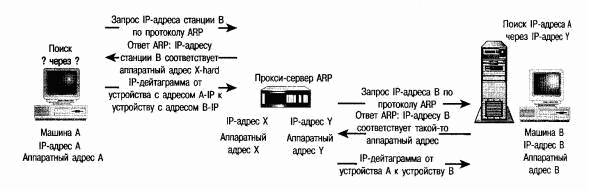
РИСУНОК 9.8. Взаимодействие рабочих станций через прокси-сервер ARP.
Протокол IP упаковывает адрес сети и адрес хоста в одно поле длиной 32 бита. Соотношение порций, выделенных для каждой части адреса, может изменяться. Это позволяет чрезвычайно эффективно использовать адресное пространство, использовать короткие IP-адреса и уменьшить общее количество сетей. Существует два принципиально различных способа разбиения адреса на две части - классовая и бесклассовая адресация (см. след. раздел).
Хосты и шлюзы
Даже некоторые специалисты иногда путают хост со шлюзом. Причиной этого является неправильное толкование термина «хост». В соответствии со стандартами RFC (1122/3 и 1009):
n Хостом (host) является устройство, подключенное к одной или более сетей. Хост в состоянии получать и отсылать поток данных любой из этих сетей, но не имеет права пересылать данные из одной сети в другую.
n Шлюзом (gateway) является устройство, подключенное более чем к одной сети. Шлюз селективно пересылает трафик из одной сети в другую.
Другими словами, раньше термины «хост» и «шлюз» являлись взаимоисключающими - ни один компьютер, даже самый производительный, не мог одновременно выступать в роли хоста и шлюза. Хостом считался компьютер, предоставляющий пользователям определенные услуги (чаще всего файловые). Современные производительные компьютеры в состоянии одновременно выполнять функции шлюза, в результате чего их ценность в глазах пользователя возрастает. Современное определение хоста звучит следующим образом:
n Хостом является устройство, подключенное к одной или более сетям. Хост в состоянии получать и отсылать поток данных любой из этих сетей. Он может выполнять функции шлюза, но этим его обязанности не ограничиваются.
Маршрутизатор (router) является выделенным шлюзом. Специально разработанное аппаратное обеспечение позволяет маршрутизатору передавать огромные объемы данных с минимальным временем задержки каждого пакета. Однако роль шлюза может выполнять стандартный компьютер с несколькими подключенными сетевыми устройствами (в том случае если сетевой уровень операционной системы поддерживает передачу пакетов). После снижения цен на выделенные маршрутизаторы компьютеры практически не используются в качестве шлюзов. Небольшие узлы, поддерживающие недорогие соединения удаленного доступа, могут использовать компьютер пользователя в качестве обычного (не выделенного) шлюза.
Классовая адресация
Сразу же после появления протокола IP его адресное пространство было разделено на части. По первому байту адреса различают следующие категории:
| 0 | Зарезервировано (для адреса сети) |
| 1-126: | Класс А (сеть: 1 байт, хост: 3 байта) |
| 127: | Зарезервировано |
| 128-191: | Класс В (сеть: 2 байта, хост: 2 байта) |
| 192-223: | Класс С (сеть: 3 байта, хост: 1 байт) |
| 224-255: | Зарезервировано (см. примечание ниже) |
ПРИМЕЧАНИЕ
Существует еще и категория широковещательных адресов, класс D. В этой главе она не рассматривается.
Если предполагается развернуть большую сеть, то, скорее всего, ей будет присвоен адрес класса А. Если же в сети находится лишь несколько хостов, ей будет присвоен адрес класса С. Приведем несколько примеров:
| IP-адрес | Адрес сети | Адрес хоста |
| 56.81.38.28 | 56 | 81.38.28 |
| 137.89.15.88 | 137.89 | 15.88 |
| 200.77.32.61 | 200.77.32 | 61 |
Выделение подсетей
Система классовой адресации прекрасно зарекомендовала себя при работе с провайдерами Internet, но не позволяет маршрутизировать пакеты внутри самой сети. Предполагается, что эту задачу возьмет на себя второй уровень (ретрансляция/коммутация). Отсутствие механизма маршрутизации в большой сети класса А связано с определенными проблемами, поскольку процессы ретрансляции и коммутирования становятся практически неуправляемыми.
Логичным решением было бы разбить большую сеть на несколько меньших сегментов, но в пределах исходной системы классовой адресации это невозможно. В рассмотренном выше примере сетевой адрес 137.89 обрабатывается как адрес класса В, что не позволяет соединить различные сегменты сети с различными узлами.
С целью решения этой проблемы каждому адресу сопоставляется новое поле маски подсети (subnet mask). Маска определяет количество байт, отведенных под сетевой адрес, и значение адреса хоста (первый байт уже лишен ключевой информации).
В маске подсети двоичная единица соответствует биту сетевого адреса, а двоичный нуль - биту адреса хоста. Например, для адреса 137.89.15.88 маску можно записать в следующем виде:
| Адрес: | 10001001.01011001.00001111.01011000 | (137.89.15.88) |
| Маска подсети: | 11111111.11111111.00000000.00000000 | (255.255.0.0) |
Таким образом маска подсети указывает на то, что первых два байта являются адресом сети, а вторые два - адресом хоста. Следовательно, маски для традиционных классов адресов равны:
n Класс А (сеть: 8 бит, хост: 24 бит): 255.0.0.0
n Класс В (сеть:16 бит, хост: 16 бит): 255.255.0.0
n Класс С (сеть: 24 бит, хост: 8 бит): 255.255.255.0
Если предполагается использовать адрес сети 137.89.0.0 с целью создания нескольких сетей класса С, можно использовать следующий адрес:
| Адрес: | 10001001.01011001.00001111.01011000 | (137.89.15.88) |
| Маска подсети: | 11111111.11111111.11111111.00000000 | (255.255.255.0) |
Процедура разбиения сети на подсети путем использования более длинных масок (например, 255.255.255.0 вместо 255.255.0.0) называется выделением подсетей (subnetting). Имейте в виду, что некоторое «древнее» программное обеспечение принципиально не желает распознавать маски подсетей и соответственно сами подсети. Например, выполняющий задачи маршрутизации служебный процесс UNIX routed использует протокол RIP version 1, который был разработан до того, как догадались присваивать подсетям маски.
Выделение подсетей с помощью масок, не выровненных на границу байта
До сих пор речь шла о масках подсети 255.0.0.0, 255.255.0.0 и 255.255.255.0. Такие маски называются выровненными на границу байта (byte-aligned subnet masks), поскольку отводят для адресов сети и хоста целое количество байт. Однако допускается с помощью не выровненных на границу байта масок выделить для адреса произвольное количество бит (хоть это и усложняет обработку адресов). Например:
| Адрес: | 10001001.01011001.00001111.01011000 | (137.89.15.88) |
| Маска подсети: | 11111111.11111111.11111111.11110000 | (255.255.255.240) |
Теперь адрес хоста описывается всего лишь четырьмя битами, что позволяет использовать внутри сети 16 адресов. Один адрес резервируется собственно для сети, еще один - в качестве широковещательного, а остальные 14 можно присвоить хост-компьютерам.
| Адрес: | 10001001.01011001.00001111.01011000 | (137.89.15.88) |
| Маска подсети: | 11111111.11111111.11111111.11110000 | (255.255.255.240) |
| Адрес подсети: | 10001001.01011001.00001111.01011000 | (137.89.15.88) |
| Широковещательный адрес: | 10001001.01011001.00001111.01011111 | (137.89.15.95) |
Обратите внимание, что адрес сети (137.89.15.80) больше не оканчивается привычным нулем, а широковещательный адрес (137.89.15.95) - привычным значением 255. Пусть эти сетевой и широковещательный адреса выглядят несколько необычно, они были созданы стандартным способом (заполнением поля адреса хоста нулями или единицами соответственно). Маска подсети тоже выглядит необычно, но она была сформирована все тем же стандартным способом.
Описываемая методика выделения подсетей позволяет создавать сети произвольной конфигурации. Например, для прямого соединения небольших сетей можно воспользоваться маской 255.255.255.252, которая отводит 30 бит под адрес сети и 2 бита - под адрес хоста. Объединяя сети небольшого размера, можно использовать маску 255.255.240.0, выделяющую 20 бит под адрес сети и 12 бит под адрес хоста (двенадцатью битами можно описать адреса 4096 хост-компьютеров).
Было бы совсем неплохо, если маску можно было бы представить количеством бит, отведенных под адрес хоста (например, маску из предыдущего примера 255.255.240.0 представить просто как 12). Согласитесь, что в таком формате маска становится достаточно наглядной. К сожалению, исторически сложилось так, что формат представления маски удобен для компьютеров, но отнюдь не для нас. Что ж, придется учиться думать в двоичном виде!
Могу посоветовать записывать маски в шестнадцатеричном, а не десятичном виде. Действительно, по сравнению со стандартной формой записи 255.255.240.0 работать с маской FF.FF.F0.00 намного приятнее. Имейте в виду, что преобразовывать числа между шестнадцатеричной и двоичной системами счисления удобнее, чем между десятичной и двоичной.
Если для определения соответствия между адресами хост-компьютерами и адресами IP используется система имен доменов, не выровненные на границу байта маски подсети следует использовать с максимальной осторожностью. Дело в том, что они лишают вас возможности управлять записями обратного поиска (reverse lookup records), отвечающими за переход от IP-адресов к именам хостов. DNS поддерживает разделение IP-адресов только на границу байта (в пределах домена in-addr.arpa.).
Объединение сетей
Процедура объединения сетей (supernetting) имеет много общего с концепцией выделения подсетей - в соответствии с маской подсети IP-адрес разбивается на две части (адрес сети и адрес хоста). Но вместо выделения в одной большой сети нескольких меньших подсетей происходит обратное - небольшие сети объединяются в одну большую суперсеть.
Предположим, что необходимо объединить 16 сетей класса С, которым присвоен диапазон адресов от 201.66.32.0 до 201.66.47.0. Общей сети можно присвоить адрес 201.66.32.0 и маску 255.255.240.0 (все адреса сети будут состоять из одних и тех же первых 20 бит, соответствующих 201.66.32.0, поскольку для объединения сети адрес хоста обнуляется).
К сожалению, далеко не всегда получается объединить сети с произвольным набором адресов - набору из 16 сетей класса С с адресами от 201.66.71.0 до 201.66.86.0 невозможно выделить единственный сетевой адрес (попробуйте его найти!). Почему? Дело в том, что заданная маска подсети 255.255.240.0 не позволяет обнулить поле хоста в начале диапазона адресов:
| Адрес | Маска подсети | Адрес сети | Адрес хоста |
| 201.66.32.0 | 255.255.240.0 | 201.66.32 | 0.0 |
| 201.66.84.0 | 255.255.240.0 | 201.66.84 | 3.0 |
К счастью, эта проблема не столь актуальна - разумно присваивая адреса, можно заранее зарезервировать подходящий диапазон.
Маски произвольной длины
Если возникает необходимость разбиения сети на несколько подсетей различного размера, можно воспользоваться масками произвольной длины (variable length subnet mask - VLSM). Этот несколько устрашающий термин на самом деле означает, что каждой подсети можно присвоить маски различной длины. В процессе разбиения сети большой компании одним подсетям можно будет присвоить маску 255.255.255.0 (для небольших подразделений компании), а другим - 255.255.252.0 (для подразделений с большим количеством пользователей).
Бесклассовая адресация
Интенсивное развитие Internet в значительной степени увеличило количество хост-компьютеров, подключенных к сети. На данный момент непосредственно к Internet подключено менее 232 компьютеров, но проблема нехватки адресов уже стала актуальной. В 1993 году разработан стандарт RFC 1519, рассматривающий вопросы бесклассовой междоменной маршрутизации (Classless Inter-Domain Routing - CIDR), который был одной из первых попыток решить проблему неэффективного распределения адресного пространства.
Стандарт CIDR пытался продлить дни существования протокола IPv4, собственно проблеме истощения адресного пространства внимание не уделялось. Протокол IPv6 решает эту проблему путем использования 128-битовых адресов вместо 32-битовых. Однако переход на использование протокола IPv6 будет достаточно болезненным, к чему сообщество Internet еще не готово. Адресация с помощью CIDR предоставляет некоторое время, необходимое для подготовки к переходу на IPv6.
Система классовой адресации неплохо себя зарекомендовала. К ее преимуществам можно отнести эффективное использование адресного пространства и минимальную нагрузку на маршрутизаторы. Однако неожиданный рост Internet выявил две неожиданные проблемы:
n Возросшее количество сетей привело к росту объема таблиц маршрутизации, что, в свою очередь, снизило производительность маршрутизаторов.
n Значительная часть адресного пространства была впустую растрачена вследствие выделения адресов блоками фиксированного размера по 256 = 28 (класс С), 65536 = 216 (класс В) или 16777216 = 224 (класс А). В результате возник дефицит адресов класса В.
Для решения второй проблемы можно было бы создать несколько меньших сетей вместо одной большой (например, вместо одной сети класса В можно развернуть несколько сетей класса С). Это несомненно позволило бы эффективнее присваивать адреса, но одновременно увеличило бы нагрузку на маршрутизаторы (мы вернулись к первой проблеме).
Схема CIDR позволяет присваивать адреса в соответствии с топологией сети. Это значит, что последовательная группа сетевых адресов может быть выделена определенному провайдеру, что позволит присвоить отдельной группе пользователей единственный (скорее всего, созданный путем объединения сетей) адрес.
Предположим, что провайдеру выделен набор из 256 сетей класса С, принадлежащих диапазону от 213.79.0.0 до 213.79.255.0. Провайдер выделяет один адрес класса С каждому клиенту, но внешние для провайдера таблицы маршрутизации будут указывать на адрес 213.79.0.0 с маской подсети, равной 255.255.0.0.
Этот метод несомненно позволит снизить темпы роста таблиц маршрутизации при выделении каждого нового адреса. По оценкам разработчиков стандарта CIDR RFC (1519), если 90% провайдеров перейдут на использование адресации CIDR, за три года таблицы маршрутизации увеличат свой объем на 54%. В противном случае за тот же период ожидается увеличение объема 776% (предполагается, что до этого адресация CIDR вообще не использовалась).
Если бы можно было осуществить перенумерацию существующего адресного пространства, количество объявленных путей установления соединения, которые вынуждены обрабатывать магистральные маршрутизаторы Internet, было значительно уменьшено. К сожалению, из-за огромного объема административных работ это практически невозможно.
Таблицы маршрутизации
Если к хосту подключено несколько сетевых устройств, каким образом он выбирает одно из них для доставки пакетов на определенный IP-адрес? Ответ кроется в таблице маршрутизации. Рассмотрим следующую таблицу маршрутизации:
| Получатель | Маска подсети | Шлюз | Флажки | Устройство |
| 201.66.37.0 | 255.255.255.0 | 201.66.37.74 | U | eth0 |
| 201.66.39.0 | 255.255.255.0 | 201.66.39.21 | U | eth1 |
Хост отсылает весь трафик, предназначенный для хостов сети 201.66.37.0 (например, для хостов с адресами 201.66.37.1-291.66.37.254), через устройство eth0 (которому присвоен IP-адрес 201.37.37.74). Весь трафик, предназначенный для хостов сети 201.66.39.0, проходит через устройство eth1 (с IP-адресом 201.37.39.21). Флажок о свидетельствует о том, что маршрут в настоящее время занят («up»).
Имейте ввиду, что в непосредственно подключенных сетях некоторое программное обеспечение не помещает IP-адрес устройства в поле шлюза (см. выше). Вместо этого в таблице фигурирует только название устройства,
В рассмотренном примере хост-компьютер принадлежит локальной сети. Как изменится ситуация, если хост будет принадлежать удаленной сети? Если вы подключаетесь к сети с адресом 73.0.0.0 через маршрутизатор с IP-адресом 201.66.37.254, в таблицу маршрутизации можно добавить следующую запись:
| Получатель | Маска подсети | Шлюз | Флажки | Устройство |
| 73.0.0.0 | 255.0.0.0 | 201.66.37.254 | UG | eth0 |
Теперь все пакеты, предназначенные для хост-компьютеров сети 73.0.0.0, будут транслироваться через шлюз 201.66.37.254. Обратите внимание, что это возможно только в том случае, если в таблице маршрутизации появилась новая запись с соответствующей информацией! Флажок G (gateway) свидетельствует о том, что данная запись направляет трафик через внешний шлюз. Аналогично с помощью флажка H (host) можно направить трафик от маршрутизатора к определенному хост-компьютеру:
| Получатель | Маска подсети | Шлюз | Флажки | Устройство |
| 91.32.74.21 | 255.255.255.255 | 201.66.37.254 | UGH | eth0 |
В этом примере рассматривается только стандартное содержимое таблицы маршрутизации (существуют еще некоторые специальные записи):
| Получатель | Маска подсети | Шлюз | Флажки | Устройство |
| 127.0.0.1 по | 255.255.255.255 | 201.66.37.254 | UH | lo0 |
| умолчанию | 0.0.0.0. | eth1 |
Первое из этих устройств (заглушка - loopback interface) направляет весь трафик от хоста на себя. Оно используется для тестирования сети и для поддержки обмена данными между приложениями, которые в нормальных условиях общаются через IP-адреса, но в данном случае вынуждены работать в локальном режиме.
В роли этого устройства выступает хост со специальным адресом 127.0.0.1 (устройство lo1 соответствует «несуществующему» сетевому адаптеру, который для стека IP является внешним).
Вторая запись представляет еще больший интерес. Для сохранения возможности трансляции абсолютно всех пакетов в таблице может быть определен маршрут по умолчанию (default route). Если ни одна запись в таблице маршрутизации не будет соответствовать адресу предполагаемого получателя, пакет будет передан определенному по умолчанию шлюзу (указанному в маршруте по умолчанию).
Большинство хост-компьютеров в сетях с несложной конфигурацией подключены через один сетевой адаптер к локальной сети, которая общается с другими посредством единственного маршрутизатора. В результате таблица маршрутизации состоит всего из записи заглушки, записи локальной подсети и записи по умолчанию (указывающей на маршрутизатор).
Перекрывающиеся маршруты
Предположим, некоторые записи в таблице маршрутизации совпадают:
| Получатель | Маска подсети | Шлюз | Флажки | Устройство |
| 1.2.3.4 | 255.255.255.255 | 201.66.37.253 | UGH | eth0 |
| 1.2.3.0 | 255.255.255.0. | 201.66.37.254 | UG | eth0 |
| 1.2.0.0 | 255.255.0.0. | 201.66.39.253 | UG | eth1 |
| по умолчанию | 0.0.0.0. | 201.66.39.254 | UG | eth1 |
Маршруты действительно совпадают, поскольку все они включают адрес 1.2.3.4. Если отослать пакет по адресу 1.2.3.4, какой маршрут будет выбран? В этом случае будет выбран первый маршрут через шлюз 201.66.37.253. Всегда выбирается маршрут с самой длинной (самой точной) маской подсети. Аналогично предназначенные 1.2.3.5 пакеты будут отосланы по второму маршруту, а не по третьему.
Внимание: Это правило применимо только к косвенным маршрутам (тем, которые направляют пакеты через шлюзы). Большинство приложений болезненно реагирует на попытку объявить в одной подсети два интерфейса. Следующий набор записей, как правило, будет признан недействительным (хотя некоторое программное обеспечение все-таки попытается обрабатывать эти устройства):
| Устройства | IP-адрес | Маска подсети |
| eth0 | 201.66.37.1 | 255.255.255.0 |
| eth1 | 201.66.37.2 | 255.255.255.0 |
Использование совпадающих маршрутов связано с несомненными преимуществами. Дело в том, что теперь можно определить используемый по умолчанию маршрут на адрес 0.0.0.0 и маску подсети 0.0.0.0 вместо того, чтобы специально описывать эту исключительную ситуацию для маршрутизирующего программного обеспечения.
Вернемся к адресации CIDR и рассмотрим пример, в котором провайдеру выделен набор из 256 сетей класса С, адреса которых принадлежат диапазону от 213.79.0.0 до 213.79.255.0. Внешние для провайдера таблицы маршрутизации указывают на единственный маршрут через адрес 213.79.0.0 и маску подсети 255.255.0.0.
А теперь предположим, что один из клиентов решил поменять провайдера. Раньше этому клиенту был присвоен сетевой адрес 213.79.61.0. Возникает логичный вопрос - необходимо ли изменить этот адрес в соответствии с выделенным новому провайдеру диапазоном адресов? Ведь тогда придется присвоить новые адреса всем машинам организации, отредактировать базу данных DNS и т.д.
К счастью, существует и менее болезненное решение. Старый провайдер сохраняет маршрут 213.79.0.0 (с маской подсети 255.255.0.0), а новый провайдер регистрирует маршрут 213.79.61.0 (с маской подсети 255.255.255.0). Поскольку новый маршрут имеет более конкретную (длинную) маску подсети по сравнению с маршрутом старого провайдера, именно он будет использоваться.
Статическая маршрутизация
Рассмотрим созданную таблицу маршрутизации, в которой на данный момент находятся шесть записей. Таблица приведена ниже, а топология сети достаточно наглядно показана на рисунке 9.9.
| Получатель | Маска подсети | Шлюз | Флажки | Устройство |
| 127.0.0.1 | 255.255.255.255 | 127.0.0.1 | UH | lo0 |
| 201.66.37.0 | 255.255.255.0 | 201.66.37.74 | U | eth0 |
| 201.66.39.0 | 255.255.255.0 | 201.66.39.21 | U | eth1 |
| по умолчанию | 0.0.0.0 | 201.66.39.254 | UG | eth1 |
| 73.0.0.0 | 255.0.0.0 | 201.66.37.254 | UG | eth0 |
| 91.32.74.21 | 255.255.255.255 | 201.66.37.254 | UGH | eth0 |
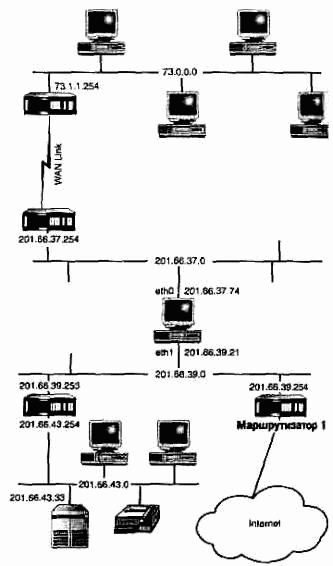
РИСУНОК 9.9. Более сложная сеть.
ПРИМЕЧАНИЕ
Вывести содержимое таблицы маршрутизации можно с помощью команды netstat -Rn. Более подробные сведения об этой команде можно найти в документации изготовителя маршрутизатора.
Каким образом эти записи очутились в таблице? Первая добавлена программным обеспечением во время инициализации таблицы маршрутизации, вторая и третья - автоматически после присвоения IP-адресов сетевым адаптерам, три последние - вручную. В системах UNIX это осуществляется с помощью команды route, которая либо явно задается пользователем, либо фигурирует в сценарии загрузки.
Все эти методы подразумевают статическую маршрутизации. Маршруты, как правило, добавляются в процессе загрузки, а таблицы маршрутизации остаются неизменными до тех пор, пока их содержимое не будет отредактировано вручную.
Протоколы маршрутизации
И хосты, и шлюзы могут использовать методику динамической маршрутизации (dynamic routing), которая позволяет обновлять таблицы маршрутизации автоматически после изменения конфигурации сети (например, после выхода маршрутизатора из строя). Функции вышедшего из строя маршрутизатора могут быть возложены на другой без вмешательства пользователя, что делает всю сеть более устойчивой к отказам аппаратного обеспечения.
Динамическая маршрутизация требует использования протокола маршрутизации, на который была бы возложена задача добавления и удаления записей из таблицы маршрутизации. Эта таблицы выполняет те же функции, что и во время статической маршрутизации, но ее записи добавляются и удаляются автоматически, а не вручную.
Различают два типа протоколов маршрутизации: внутренние и внешние. Внутренние протоколы (interior protocols) используются в пределах (внутри) одной автономной системы, в то время как внешние протоколы (exterior protocols) - между автономными системами. Под термином «автономная система» подразумевается сеть, принадлежащая определенной административной единице (это может быть большая компания или университет). Небольшие узлы, как правило, являются частью автономных систем провайдеров Internet.
Поскольку далеко не все специалисты имели счастье работать с внешними протоколами (а некоторые даже не догадываются об их существовании!), в этой главе будут рассмотрены только внутренние протоколы. Наиболее распространенными из них являются EGP (Exterior Gateway Protocol - протокол внешнего шлюза) и BGP (Border Gateway Protocol - протокол крайнего шлюза). Протокол BGP появился недавно и постепенно заменяет EGP.
Переадресация ICMP
Протокол ICMP (Internet Control Messages Protocol - протокол передачи управляющих сообщений в Internet) нельзя рассматривать в качестве чистого протокола маршрутизации. Тем не менее он поддерживает переадресацию, что позволяет рассматривать его вместе с остальными протоколами маршрутизации. Предположим, что таблица маршрутизации состоит из шести записей. Необходимо переслать пакет для хост-компьютера, за которым закреплен адрес 201.66.43.33. Анализ таблицы показывает, что для этого адреса подходит только определенный по умолчанию маршрут, который соответствует пересылке трафика через маршрутизатор 201.66.39.254 (см. путь 1 на рисунке 9.10). Однако этот маршрутизатор располагает всеми сведениями о сети и передает все пакеты для подсети 201.66.43.0 через маршрутизатор 201.66.39.254. Тот также передает пакет соответствующему маршрутизатору (см. путь 2 на рисунке 9.10). Пакет был бы доставлен намного быстрее в том случае, если бы хост направил его сразу же через маршрутизатор 201.66.39.254 (см. путь 3 на рисунке 9.10).
Маршрутизатор заставляет хост-компьютер использовать иной путь, пересылая ему служебные данные ICMP. Маршрутизатору известен оптимальный путь, поскольку ответный пакет отослан не по тому пути, по которому он первоначально получен. Хотя маршрутизатор знает, что вся подсеть 201.66.43.0 обслуживается маршрутизатором 201.66.39.254, в нормальных условиях он ограничивается пересылкой запроса переадресации ICMP определенному хосту (201.66.43.33 в данном случае). Хост-компьютер создает новую запись в таблице маршрутизации.
| Получатель | Маска подсети | Шлюз | Флажки | Устройство |
| 201.66.43.33 | 255.255.255.255 | 201.66.39.253 | UGHD | eth1 |
Обратите внимание на флажок D (redirect) - он установлен для всех маршрутов, созданных с помощью переадресации ICMP. Впоследствии все пакеты будут пересылаться по новому маршруту (путь 3 на рисунке 9.10).
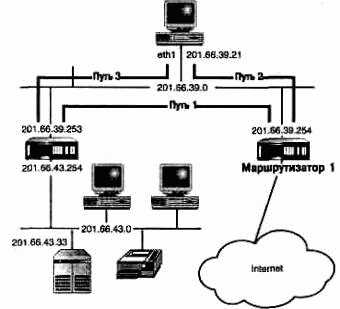
РИСУНОК 9.10. Переадресация ICMP.
Протокол RIP
Протокол обмена информацией о маршрутизации (Routing Information Protocol) является несложным внешним протоколом маршрутизации, который успешно используется на протяжении вот уже нескольких лет и успел заслужить широкую популярность (команда UNIX routed использует именно протокол RIP), Протокол использует алгоритм дистанционно-векторной маршрутизации, который выбирает маршрут путем сравнения количества пролетов между двумя точками. Каждый маршрутизатор, через который необходимо пройти пакету, также считается пролетом.
Использовать протокол RIP могут как хосты, так и шлюзы. Однако хосты в состоянии только получать информацию - им отказано в праве передачи данных. Информация может быть специально затребована от шлюза, но помимо этого каждые 30 секунд содержимое таблиц маршрутизации обновляется- Для обмена данными между хостами и шлюзами через порт 520 протокол RIP прибегает к помощи протокола передачи пользовательских дейтаграмм (UDP).
Передаваемая между шлюзами информация накапливается с целью построения таблицы маршрутизации. Выбранный протоколом RIP маршрут всегда будет кратчайшим с точки зрения количества пролетов.
Первая версия протокола RIP вполне приемлемо работает в несложных, относительно небольших сетях. При попытке использовать этот протокол в больших сетях начинают появляться серьезные проблемы. Некоторые из них устранены во второй версии протокола (RIP v2), а некоторые так и остались неразрешимыми. В последующем обсуждении, если на то нет особых указаний, речь идет о характерных для обеих версий особенностях.
Протокол RIP не учитывает качества каналов связи - с его точки зрения все каналы идентичны. Медленное соединение через последовательный порт ничем не отличается от высокоскоростного волоконно-оптического канала. Протокол RIP отдает предпочтение маршруту с минимальным количеством пролетов. Если придется устанавливать соединение по одному из следующих каналов:
n Волоконно-оптический канал 100 Мбит/с, подключенный через маршрутизатор к Ethernet 10 Мбит/с
n Соединение через последовательный порт 9600 бит/с
Протокол RIP выберет последний вариант. Кроме того, протокол не учитывает интенсивность трафика канала. Из двух каналов Ethernet, один из которых чрезвычайно загружен, а второй практически свободен, протокол RIP сможет выбрать именно загруженный.
Рассматриваемый протокол в состоянии учитывать до 15 пролетов. Если маршрут будет состоять более чем из пятнадцати пролетов, он будет считаться недоступным. Именно поэтому в очень больших автономных системах, где количество пролетов на большинстве маршрутов превышает 15, использовать протокол RIP нецелесообразно.
Первая версия RIP не распознает выделенные подсети - маска подсети не передается по каждому маршруту. Метод определения маски подсети для каждого маршрута по-разному реализован у различных изготовителей. Вторая версия протокола RIP v2 устраняет этот недостаток.
Протокол RIP обновляет данные таблиц каждые 30 секунд, поэтому информация о выходе из строя канала будет распространяться по большой сети некоторое время. На распространение информации о возобновлении функционирования устройства потребуется еще больше времени, в течение которого могут открываться замкнутые маршруты.
Подведем итог. RIP является несложным протоколом маршрутизации, который характеризуется некоторыми ограничениями (особенно первая версия). Тем не менее для определенного типа систем его использование довольно часто является единственной приемлемой альтернативой.
Резюме
Протокол разрешения адресов (ARP) используется для поиска соответствия между IP-адресам и аппаратными адресами (МАС-адресами). Этот прозрачный протокол заявляет о своем существовании только после конфликта IP-адресов. В исключительных ситуациях кэш-таблица ARP может быть отредактирована вручную с помощью команды arp.
Адрес IP разбивается на две части: адрес сети и адрес хоста. Способ разбиения зависит от класса сети, который определяется значением первого байта адреса. Современные реализации IP вводят дополнительное поле маски подсети, которое также определяет способ разбиения адреса. Функциональные возможности маршрутизации протокола IP возрастают, увеличивая одновременно нагрузку на маршрутизаторы и шлюзы.
Таблицы маршрутизации могут быть статическими или динамическими. Статические маршруты открываются вручную или с помощью последовательности команд в сценарии загрузки. Динамические маршруты управляются служебным процессом, запущенным протоколом маршрутизации, например, RIP или OSPF. Хотя, строго говоря, ICMP не является протоколом маршрутизации, он в состоянии изменять таблицы маршрутизации с целью переадресации сообщения.
Предыдущая | Оглавление | Следующая
| Главная | Главная по Компьютерным сетям |